

Imagine the power of instant analysis at your fingertips. The ad-hoc quick check in ARIS Process Mining, allows you to dive deep into your processes whenever you need to, giving you the flexibility to explore, analyze, and understand your operations on your terms.
In this best practice, I want to introduce the feature by providing an easy example and explaining the calculations and outcomes in detail.
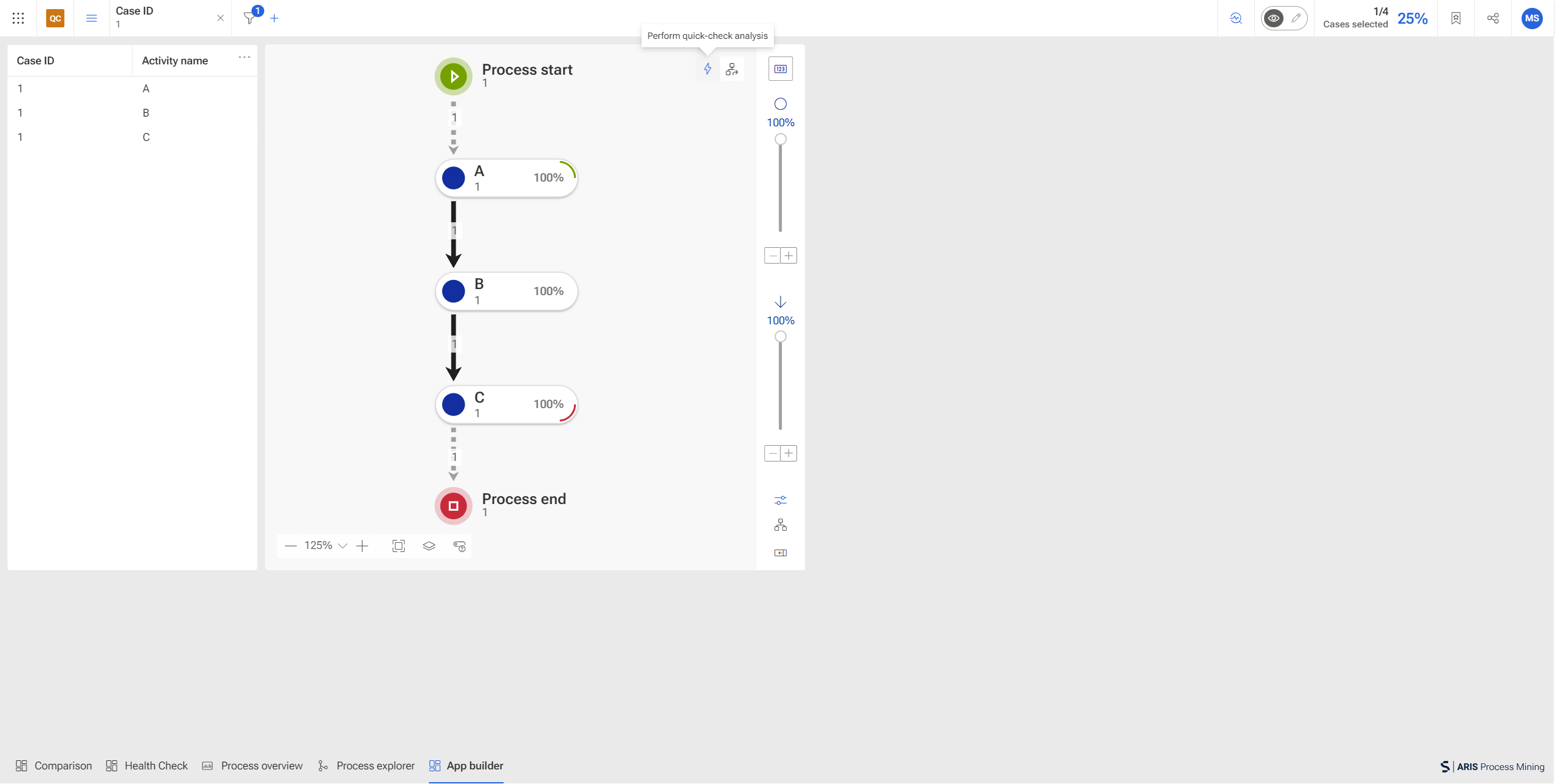
The quick check allows us to compare two sets of processes that are represented by their activities and their connections. To understand how it works I will introduce a simple example:
Let’s imagine we have a process flow that consists of activities A, B, C, and D as well as with a process explorer that looks like this:

Description automatically generated" width="228" height="344">
The cases are represented with the following connections:
C1 = [A -> B -> C]
C2 = [A -> B -> C -> D]
C3 = [A -> C -> B -> D]
C4 = [A -> C -> D]
Now, let’s compare C1 with all other cases (C2 - C4). For this, select C1 representing the first process variant in our example.
Description automatically generated" width="329" height="329">
With the selection, we have covered the following connections:
S = {A->B, B->C} with the activities A(S) = {A, B, C}
The complete dataset consists of the following connections:
D = {A->B, B->C,C->D, A->C, C->B, B->D} with the activities A(D) = {A, B, C, D}
To trigger a comparison, let’s simply perform a quick check analysis.
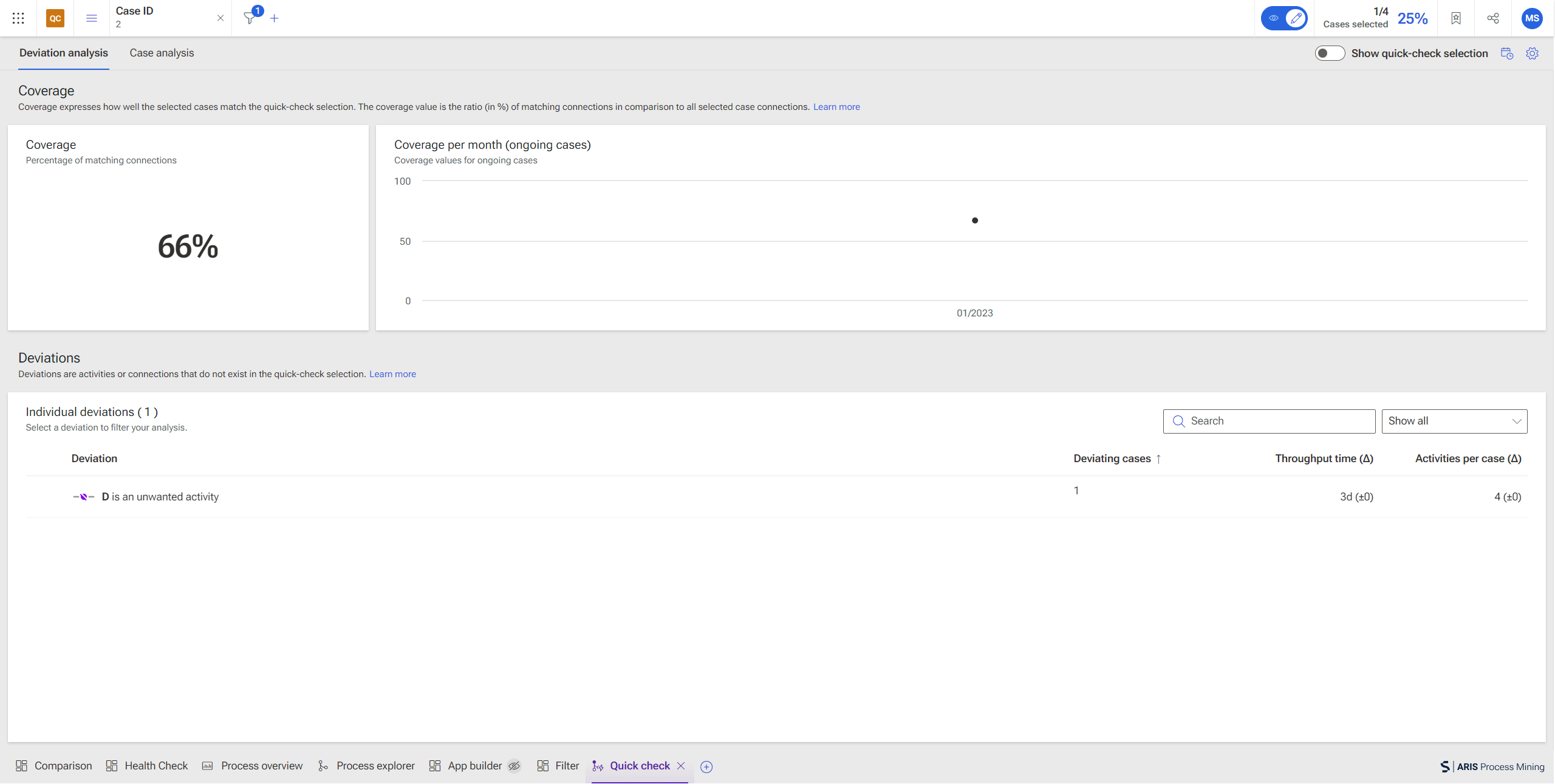
The quick check consists of two tabs: the deviation analysis, which expresses the coverage of the selected cases and the individual deviations, and the case analysis, which determines the impact of deviations on the case performance.
Deviation Analysis
The deviation analysis shows the deviations of the selected connections compared to the complete dataset. We have two kinds of deviations, those that are based on the activities and their existence and those that are based on the connections and their order. The tab additionally includes some other components like the coverage rate.
We have covered the following activities and connections in the selection:
S = {A->B, B->C} with the activities A(S) = {A, B, C}
The complete dataset consists of the following other connections:
D = {A->B, B->C,C->D, A->C, C->B, B->D} with the activities A(D) = {A, B, C, D}
Coverage
We also see a coverage value of 40%. This is calculated based on the individual connections. In our example, we have this multiset of connections:
DI = [A->B, A->B, A->C, A->C, B->C, B->C, B->D, C->B, C->D, C->D]
with size |DI|= 10
and the following multiset of connections as the quick check selection:
SI = [A->B, B->C].
The coverage is the ratio (in %) of matching connections in comparison to all selected case connections. We can see now that the 2 connections in SI occur4 times in DIand the size of DI is 10:
Coverage = | Occurrence of SI in DI | / |DI|
In our example:
Coverage = | 4 | / | 10 | = 40%
Activity deviations
The quick check now compares activities that have been included (A, B, C) which leads to the result that
![]() D is an unwanted activity as it does exist in D but not in S.
D is an unwanted activity as it does exist in D but not in S.
Connection or order deviations
Moreover, it will also compare the function flows which will lead to the result that
![]() C must not occur after A and
C must not occur after A and
![]() B must not occur after C.
B must not occur after C.

Description automatically generated" width="602" height="303">
Let’s now have a look at what the second tab offers and how the impact is calculated.
The case analysis section consists of two parts: the overview of the cases (matching cases) and the impact of the deviations on certain KPIs.
Case analysis
Matching cases
Based on the selection we have defined in the process explorer, we see the statistics that we have exactly 1 matching case and 3 deviating cases. How do we get to these numbers?
A matching case is a case that 100% matches the selected connections. For this, we need to have a look at the cases that are in the dataset.
C1 = [A->B->C]
C2 = [A -> B -> C -> D]
C3 = [A->C->B->D]
C4 = [A->C->D]
We started the quick check with the following set of connections S = {A->B, B->C}.
By manually comparing the cases and their connections, we see that there is no deviation in C1, but deviations in all other cases (C2 - C4). This leads to the result that we have exactly 1 matching case and 3 deviating ones; hence, a matching rate of 25%
Matching rate = (matching cases / all cases)
In our example:
Matching rate = 1 / 4 = 25%
Impact of deviations
The impact of deviations is calculated on a case basis as well. For this, it compares the KPIs of matching cases to non-matching cases.
In our example, let’s assume the following throughput times (TT) per case:
TT(C1) = 2d
TT(C2) = 3d
TT(C3) = 3d
TT(C4) = 2d
As C1 is the only matching case the throughput time is 2d, the mean of the throughput time of C2-C4 is 2.67d; hence, the impact is +0.67d, which corresponds to +16h.

Description automatically generated" width="602" height="303">
Filtering in the Quick Check
As the quick check app behaves like all other apps, applied global filters are considered accordingly and the result and all calculations are impacted based on them. Let’s look how this works.
Let us use the process explorer on the left to trigger the quick check based on C1, which will result in the same result as in the example above.
Let’s then apply a global filter for C2 in the process explorer on the right.

Description automatically generated" width="602" height="303">
The result is then:
![]() D is an unwanted activity.
D is an unwanted activity.
The reasoning is the same as mentioned in the example above, but the filter will reduce the dataset accordingly.
Again, the selection is:
S = {A->B, B->C}
The initial dataset was:
D = {A->B, B->C,C->D, A->C, C->B, B->D} with the activities A(D) = {A, B, C, D}
Now, it is reduced by the applied filter (C2), so that the resulting dataset is:
D = {A->B, B->C,C->D} with the activities A(D) = {A, B, C, D}
Hence, the only deviation is that activity D is not covered by the quick check selection and thus an unwanted activity.
Description automatically generated" width="602" height="303">
Please find the example attached to this post, so you can simply import the solution and try to reproduce it.
Let’s apply our learnings to a more sophisticated example
A more sophisticated example is the order-to-cash process sketched below. Identical to the simple example, the process explorer on the left is compared to the full set of cases shown on the right. Given the more sophisticated example, the quick check findings are more complex.

Description automatically generated" width="602" height="258">
More use cases and examples are also described in the post here: https://www.ariscommunity.com/users/mscheid/2023-12-08-streamlining-process-analysis-process-mining-quick-check-aris-pr…
Ultimately, dynamic checking for the impact of deviations in a process mining project aligns with the dynamic nature of modern business environments. It enables organizations to stay agile, responsive, and focused on continuous improvement, fostering operational excellence in an ever-evolving landscape.